上過 AI 課,甚至可能還買過網上提示詞合集的你,是不是還在這樣寫提示詞?
像什么在提示詞里一步步拆解思維鏈,才能讓模型學會分步思考;要給幾個例題,幫助模型理解你的問題;還要引導模型 cosplay,讓模型給出更專業的答案等等的小技巧,不少差友應該也早就活學活用了。
沒錯,說的就是火鍋

但,這些曾經讓你事半功倍的神級提示詞,可能已經過時了。
這么說吧,在不知不覺的中,大模型其實已經分成了兩派:傳統通用大模型和推理大模型。
比如 GPT-o1,它可不是 GPT-4o 的直屬版本升級。4o 屬于通用大模型,o1 已經是推理模型了。
類似的,DeepSeek 默認使用的 V3 版本是通用大模型,點擊左下角深度思考按鈕使用的才是 R1 推理模型。
而在推理模型時代,越詳細的提示詞,反而可能會讓 AI 變更蠢。
比如 OpenAI 的官方文檔里,推理模型的專欄下,就明確表示,用過于精確的提示詞,或者是引導思考這類提示詞寫法,反而會讓回答效果下降。
他們甚至還直接建議,讓大家少用思維鏈提問。。。問題直接問就行。實在效果太拉垮了,再發具體例題,讓 AI 學習。

我們還翻了一下 DeepSeek-R1 的官方技術報告,他們在論文里也這么說:“DeepSeek-R1 對提示詞很敏感,舉例提示反而會降低模型表現。"
因此,為讓效果更好,他們建議用戶直接描述問題,別舉例子。

除了 GPT 和 DeepSeek,Claude 3.7 Sonnet 也在官方文檔中表示,比起那些看似很有邏輯,每一步都詳細列出具體做啥的提示詞,他們更希望你直接使喚它。
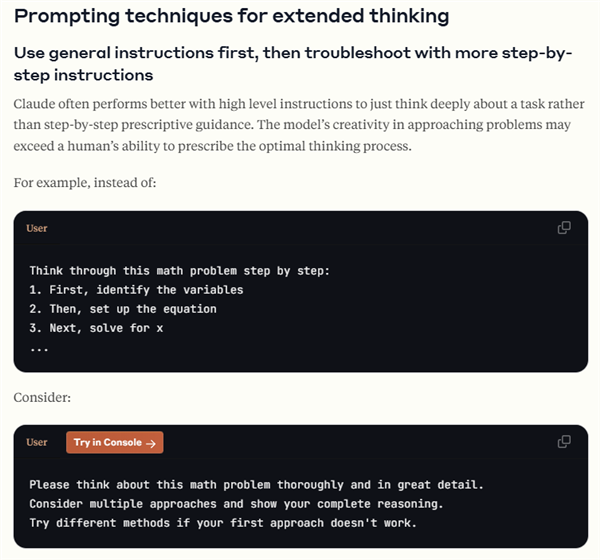
總結一下,和大伙們印象中提示詞越詳細,AI 效果就越牛的刻板印象不一樣,目前各大官方對自家推理大模型提示詞的共同建議,就是直接,簡潔,描述準確。
我們也嘗試著做了一個實驗,而最終的實驗結果同樣證明,過去非推理模型的古法提示詞,用到推理模型那里真的會讓性能下降。
我們從 leetcode 里面挑選了幾十道各種類型的困難題目,在 ChatGPT 上進行測試。咱們先按老法子寫了一段提示詞,比如暗示它做一名程序員、要進行思維鏈思考、還給出了大量示例等等等。。。

結果對于大部分題目,不論提示詞是長是短,推理模型 o1 都能給出正確的代碼,甚至能擊敗 70% 以上的人,可以說表現已經相當優秀了。
但是在 1147、471、458、1735、1799 這些題目中,o1 在老提示詞下失敗了。其中,有一題更是直接卡死,不想玩啦。
但當我們不讓它 cosplay,也不給例題,去掉思維鏈引導時,o1 這回居然在同樣的問題上又答對了。

所以,到底是啥讓昔日的提示詞小甜甜,在推理模型時代變成了牛夫人?
其實背后最主要的原因,是傳統非推理模型和推理模型的思考問題方式變了,而它們思考方式的變化源于訓練方式的不同。
傳統的大模型一般采用無監督學習和監督微調,也就是給個數據集,讓它自己去找規律。它的終極目標是根據提示詞,一個一個猜對回答里的所有字。
說人話就是,通用大模型能力很強,但沒啥子主見,這就比較吃用戶的操作了。你給的提示詞越詳細,越能讓大模型按照你的心意去做事。

但推理大模型不一樣,在原來的基礎上,它又加上了強化學習等基于推理的訓練方法。
這樣的訓練過程,會引導大模型盡量給出完整且正確的思維鏈,讓它能夠判斷這么想是不是對的。
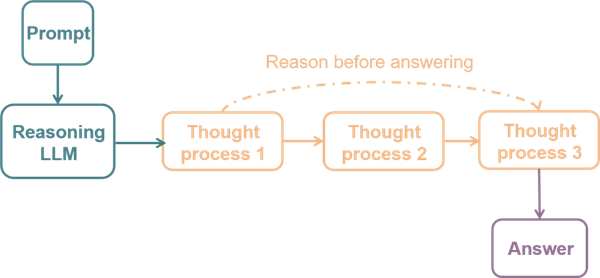
這下模型本身就有很強的 “ 主見 ”,或者說是推理能力。你要是再一步步詳細地去教它做事,反而可能和它本身的推理能力沖突了。
比如我們在實驗中發現,用老提示詞讓 o1 解決一些數學相關的編程題目時,翻車概率尤其的高。
這有可能是因為提示詞只讓它做了一名 “ 資深程序員 ”,而不是 “ 數學很好的程序員”。
我們也翻了不少模型的官方文檔,它們給出的建議也基本都是別整花花腸子,提示詞簡單直接,并且準確最好。除此之外,可以強制延長推理時間,提示它 “ 多想想 ”,或者 “ 反思你的結果 ”。
一部分老辦法也還是好用的,比如適當用些符號,把問題的結構分分清楚,或者明確你的最終目標和結果格式。
這些辦法,都能讓推理模型的效果更秀更 6。

所以,適當放下助 AI 情節,講清楚你的需求,雙手插兜尊重 AI 操作,反而可能是最有效率的。
而我覺得隨著大模型能力的不斷進化,寫提示詞這件事的門檻,也肯定會越來越低。
但,要是問提示詞工程這手藝,會不會完全消失?我們也請教了一下曾寫出“漢語新解”等神級提示詞的大神李繼剛老師。
他是這么回答的:只要我們不同的輸入,還會帶來不同的輸出,那提示詞工程就一直都在。
最后,差評前沿部覺得,對我們這些用戶來說,隨著模型能力的加強,咱也應該更新一下提示詞的彈藥庫了,別再抱著那古早的過時提示詞,當個寶了。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



